Sommaire
Empêcher Google d’indexer une page répond à des besoins techniques bien définis : pages de panier, comptes utilisateurs, contenus dupliqués ou environnements en développement. Trois méthodes couvrent l’essentiel : la balise meta noindex pour un contrôle granulaire par URL, le fichier robots.txt pour bloquer l’indexation à l’échelle d’un répertoire, et Google Search Console pour désindexer des pages déjà référencées. Le choix entre ces approches dépend directement du contexte technique.
La balise noindex pour bloquer l’indexation d’une page
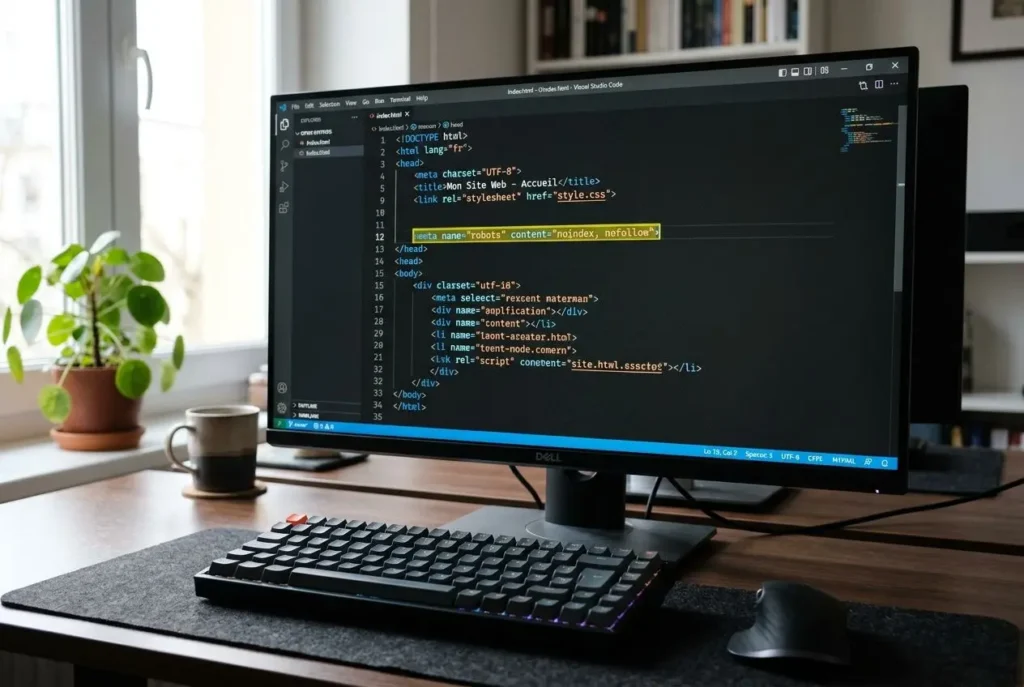
La balise meta noindex est la méthode la plus précise pour empêcher Google d’indexer une page spécifique. Elle s’insère dans la section HTML du code source via <meta name="robots" content="noindex"> et se distingue du robots.txt sur un point clé : elle autorise Googlebot à crawler l’URL mais lui interdit d’en intégrer le contenu à l’index.
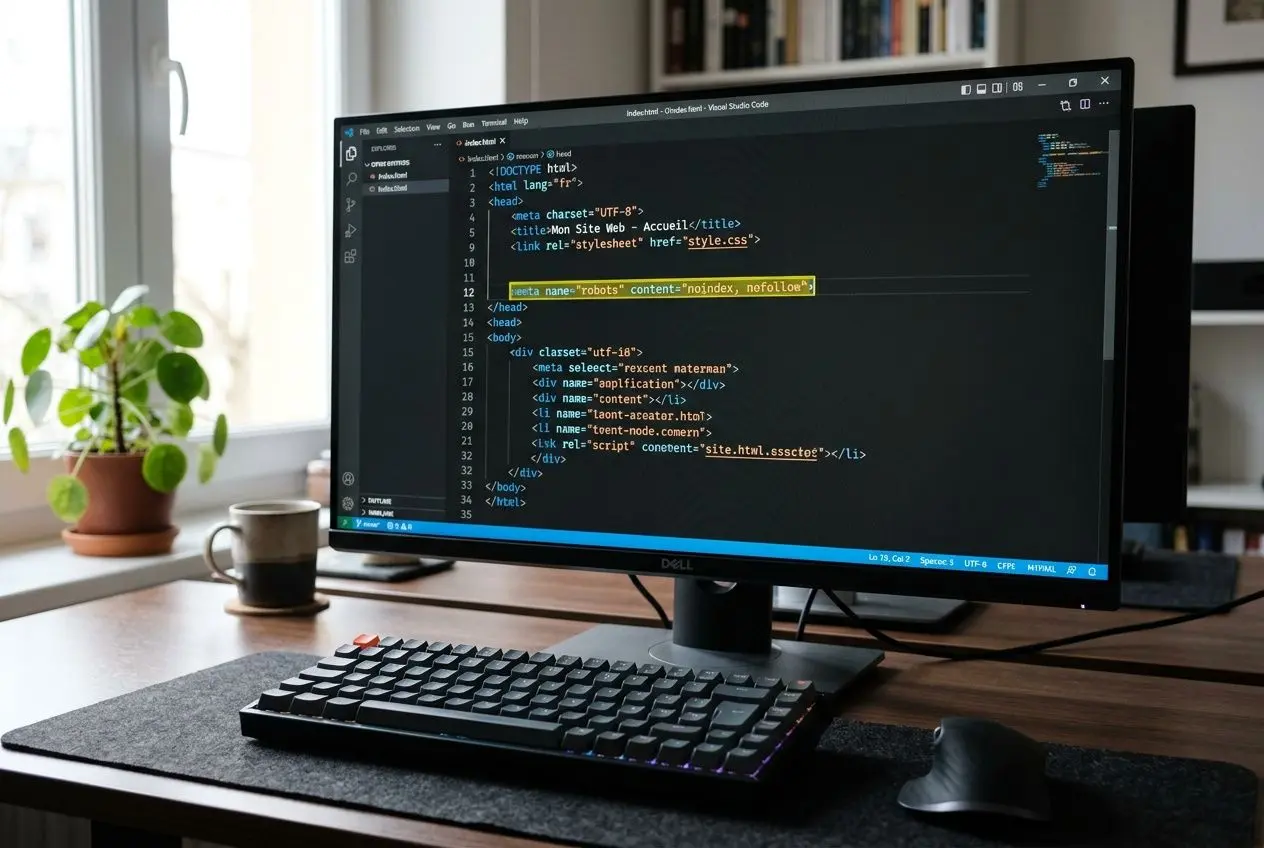
Comment implémenter la balise noindex manuellement
L’implémentation manuelle de la balise meta noindex requiert un accès direct aux fichiers serveur et une maîtrise du HTML. Ouvrez le fichier source de la page concernée, localisez </head> et insérez <meta name="robots" content="noindex"> juste avant. Cette approche garantit un contrôle total sans dépendance à un plugin tiers, particulièrement adaptée aux pages inutiles ou sensibles.
Pour cibler uniquement Googlebot, utilisez <meta name="googlebot" content="noindex"> à la place de la directive robots générique. D’autres variantes affinent le contrôle : noimageindex bloque uniquement les images; <meta name="googlebot" content="unavailable_after: 2025-12-31T23:59:59 UTC"> déclenche la désindexation après une date précise, effective environ 24h après expiration. Sauvegardez puis redéployez le fichier sur votre serveur.
Noindex via Yoast SEO et Rank Math sur WordPress
Yoast SEO permet d’ajouter la directive noindex sans toucher au code source. Dans l’éditeur WordPress, accédez à l’onglet Avancé, puis au champ Méta Robots Index : cochez Non. Yoast injecte automatiquement la balise meta noindex, c’est la ligne qui indique aux moteurs de recherche de ne pas référencer la page, sans intervention manuelle sur le HTML.
Rank Math propose une alternative fonctionnellement équivalente. Ouvrez le panneau Rank Math dans l’éditeur, localisez l’option Indexation et sélectionnez Noindex : le plugin applique immédiatement la directive aux métadonnées. Ces deux solutions réduisent les risques d’oubli et permettent une gestion cohérente de l’indexation des pages à grande échelle, avec un audit visuel depuis le tableau de bord WordPress.
Vérifier la prise en compte de la balise noindex
Après ajout de noindex, utilisez l’outil Inspecter une URL de Google Search Console pour confirmer la détection de la directive. Collez l’URL dans la search console : le rapport indique si Googlebot a bien lu la balise noindex et comment il l’a interprétée.
La suppression de l’index est progressive, Googlebot peut mettre plusieurs semaines, voire plusieurs mois, à revisiter une URL selon la fréquence d’exploration de votre site. Déclenchez un re-crawl via l’outil d’inspection pour accélérer la désindexation. Suivez l’avancement dans le rapport Indexation des pages pour tracker l’état de chaque URL désindexée. Le fichier robots.txt reste une option complémentaire pour bloquer l’indexation au niveau d’un répertoire entier, sans passer par une balise noindex page par page.
Configurer le fichier robots.txt pour contrôler le crawl
Le fichier robots.txt se situe à la racine du domaine (www.exemple.com/robots.txt) et pilote l’exploration par les robots. Contrairement à noindex, qui intervient au niveau de l’indexation, robots.txt contrôle l’accès au crawl : les directives bloquent la visite de certaines URL sans désindexer les pages déjà présentes dans Google.

Structure et directives du fichier robots.txt
Le fichier robots.txt structure le blocage du crawl via trois directives principales : User-agent identifie le robot cible (* pour tous); Disallow interdit l’accès; Allow autorise explicitement au sein d’un répertoire bloqué. Un fichier robots.txt mal configuré dégrade sévèrement le référencement en bloquant accidentellement des pages critiques.
- Disallow: / Bloque l’intégralité du site à tous les robots d’exploration, utilisé uniquement en développement ou staging.
- Disallow: /wp-admin/ ou /panier/ Bloque un répertoire spécifique sans affecter le répertoire parent ni les fichiers voisins.
- Disallow: /mentions-legales Bloque une URL unique précise sans impact sur les autres pages, utile pour les pages sensibles.
Une page bloquée via robots.txt mais déjà indexée reste dans l’index Google. Les robots malveillants ignorent les directives robots.txt, c’est pour ça qu’il faut coupler cette approche avec noindex ou une authentification pour une protection fiable. Testez chaque modification dans l’outil de test de Search Console avant la mise en production.
Robots.txt vs noindex : quelle méthode choisir
Robots.txt agit au niveau du crawl, l’accès à la page, tandis que noindex agit au niveau de l’indexation. Pour désindexer une page déjà référencée, noindex est la bonne approche : robots.txt ne supprimera pas ce qui est déjà indexé. Bloquer un répertoire entier comme /wp-admin/ ou /wp-includes/ via robots.txt reste plus efficace qu’appliquer noindex sur chaque fichier individuellement.
La stratégie optimale combine les deux méthodes : robots.txt pour les zones sensibles, administration, panier, uploads privés, et noindex pour les pages inutiles ou en doublon qu’on souhaite crawler mais pas indexer. Pour les sites en construction, robots.txt + noindex + authentification HTTP + whitelist d’IP offre une protection maximale.
| Méthode | Niveau d’action | Cas d’usage idéal | Temps de prise en compte |
| Noindex | Indexation (page par page) | Désindexer pages sensibles en production | Plusieurs semaines |
| Robots.txt | Crawl (répertoire) | Bloquer répertoires entiers (/admin/, /cache/) | Immédiat (prochaine visite) |
| Authentification.htaccess | Accès (IP ou mot de passe) | Environnements staging, zones d’administration | Immédiat |
| Suppression Search Console | Index (temporaire 6 mois) | Urgence : retrait rapide avant noindex/404 | Heures à jours |
Tester et valider le fichier robots.txt avec Search Console
Avant déploiement, utilisez l’outil de test robots.txt dans Google Search Console : accédez à Paramètres > Fichier robots.txt, collez vos directives ou modifiez directement dans l’éditeur intégré. L’outil simule le crawl et affiche précisément quelles URL sont bloquées, évitant les erreurs coûteuses en production.
Vérifiez que /wp-admin/ est bien bloqué, que /index.php et /sitemap.xml ne le sont pas, et que les images et CSS restent accessibles pour indexer une page correctement. Un seul Disallow:.js mal placé peut bloquer tous vos scripts et casser visuellement le site dans les résultats de recherche. La suppression d’une règle mal configurée passe par la même console avant chaque mise en production.
Désindexer une page via Google Search Console
Google Search Console expose trois leviers opérationnels pour piloter l’indexation des pages : l’outil de suppression d’URL pour une désindexation rapide sur 6 mois, le rapport d’indexation pour identifier les anomalies, et l’inspection d’URL pour vérifier l’interprétation exacte par Googlebot. Ces fonctionnalités couvrent aussi bien les urgences que le contrôle de cohérence des directives noindex et robots.txt.
Utiliser l’outil de suppression d’URL pour désindexer
La Google Search Console propose un outil dédié pour demander le retrait temporaire d’une URL des résultats de recherche. Le chemin : Résultats de recherche > Suppressions > Nouvelle demande de suppression, puis saisie de l’URL ciblée. Google retire la page pendant environ 6 mois, ce qui laisse le temps de déployer une solution définitive, balise noindex, renvoi 404 ou suppression physique.
- Suppression temporaire (6 mois) Idéale pour urgences : retrait rapide avant mise en place de noindex ou 404 définitif.
- Ajout de noindex + re-crawl Après suppression temporaire, ajoutez la balise noindex et soumettez une demande de re-crawl via Inspecter une URL pour désindexation définitive.
- Renvoi HTTP 404 ou 410 Pour suppression définitive : 404 signifie page non trouvée (temporaire), 410 signifie disparu à jamais (préférable pour Google).
- Protection par mot de passe Bloque l’accès à Googlebot, empêchant l’indexation sans supprimer la page physiquement.
La suppression temporaire ne remplace pas une stratégie long terme : après les 6 mois, la page peut être ré-indexée automatiquement si aucune balise noindex n’est en place. Combinez systématiquement l’outil de suppression de la Search Console avec un noindex ou un 404 pour un résultat durable.
Surveiller l’indexation avec le rapport dédié
Le rapport d’indexation des pages (Indexation > Pages) donne une vue complète des pages indexées, bloquées ou exclues par Googlebot. Il remonte les pages marquées noindex involontairement, les erreurs 5xx, les redirections cassées et les URL exclues par le fichier robots.txt. Cette granularité permet d’auditer l’état d’indexation et de corriger les anomalies avant impact SEO.
Une hausse soudaine de pages exclues signale un problème concret : robots.txt trop restrictif, noindex mal appliqué, erreurs serveur. Cliquez sur chaque statut pour accéder aux listes détaillées; exportez les données pour corréler les baisses de trafic avec des modifications d’indexation dans le temps.
L’outil Inspecter une URL complète ce monitoring : pour chaque URL testée, il affiche l’interprétation exacte par Googlebot, noindex détecté, ressources bloquées, redirections actives, code de réponse HTTP. Utilisez-le systématiquement après toute modification pour confirmer que la stratégie visant à bloquer l’indexation fonctionne comme prévu. Ce guide détaille comment empêcher indexation Google en combinant balise noindex, fichier robots.txt, outil de suppression d’URL et option native WordPress pour un contrôle global de la désindexation.
Foire aux questions
Quelle est la différence entre robots.txt et la balise noindex pour empêcher Google d’indexer une page ?
robots.txt contrôle le crawl : il empêche Googlebot de visiter une URL ou un répertoire entier. La balise noindex agit en aval, elle autorise l’exploration mais bloque l’ajout à l’index. Une page déjà indexée et bloquée via robots.txt reste dans Google; ajouter noindex déclenche sa désindexation progressive.
Pour empêcher Google d’indexer une page déjà visible dans les résultats, noindex est le levier pertinent. robots.txt excelle à protéger des répertoires entiers comme /wp-admin/ ou /uploads/temp/, où l’accès de Googlebot n’a aucune utilité.
Combien de temps faut-il pour qu’une page soit désindexée après ajout de noindex ?
La désindexation s’opère lors du prochain passage de Googlebot, selon la fréquence d’exploration du site : quelques jours pour un site crawlé quotidiennement, plusieurs mois pour un site dont le crawl est mensuel. Le délai dépend directement de la cadence d’exploration configurée et observée.
Pour accélérer la prise en compte, soumettez une demande de re-crawl via la fonction « Inspecter une URL » dans Google Search Console : cela signale à Google de revisiter l’URL en priorité.
Comment vérifier qu’une page n’est plus indexée par Google ?
Trois vérifications complémentaires suffisent : inspectez l’URL dans Search Console pour confirmer que noindex ou 404 est détecté; consultez le rapport d’indexation des pages pour vérifier que l’URL disparaît bien des pages indexées; testez directement via site:votredomaine.com/page-url dans Google, l’absence de résultat confirme que la page n’est plus indexée.
Attendez quelques jours après l’ajout de noindex avant de conclure : Search Console elle-même ne reflète pas l’état en temps réel, et empêcher Google d’indexer une page ne produit pas d’effet instantané côté index.